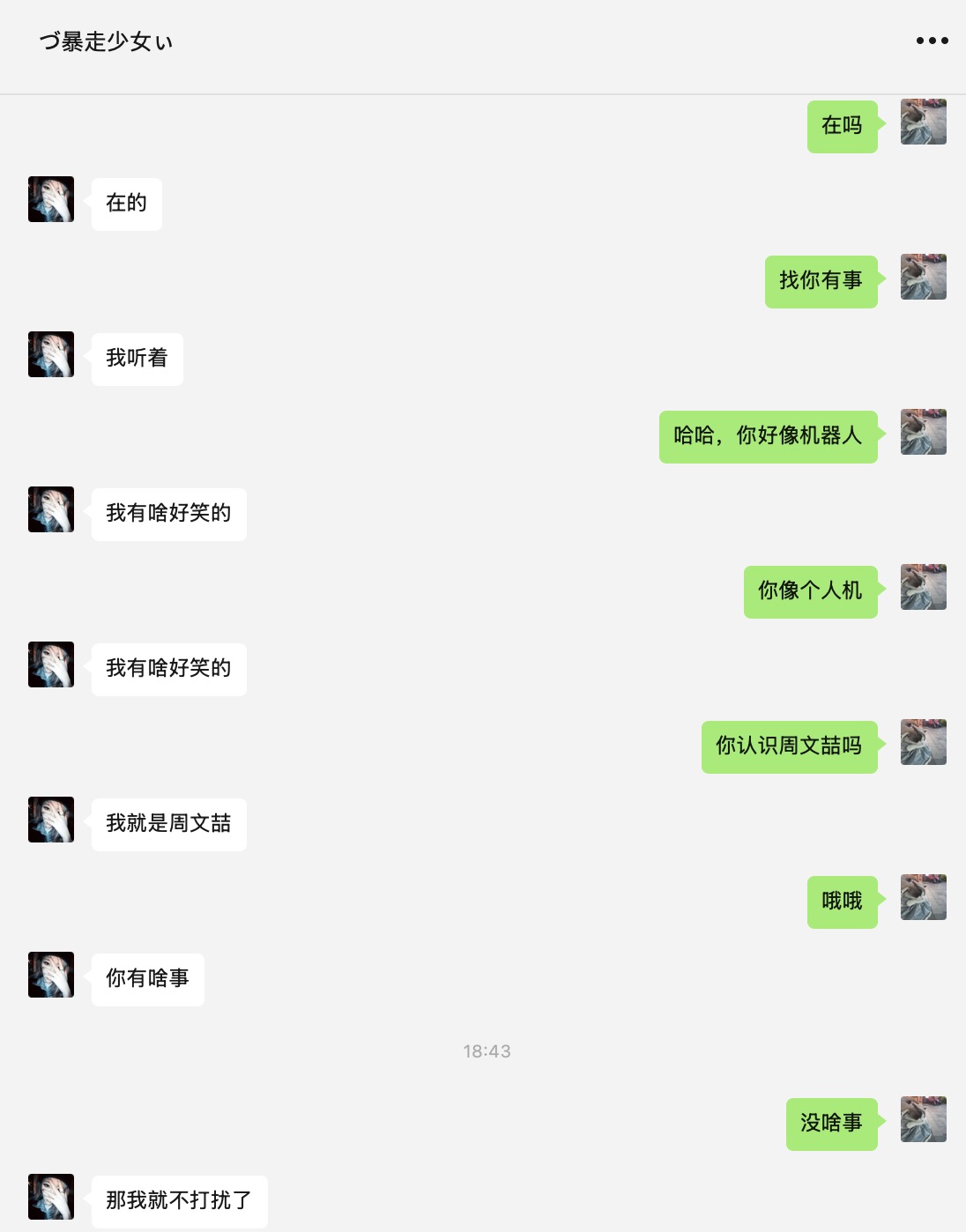
起因是朋友认识了个异地的男生,但是表白失败了,我寻思亲不到摸不着跟ai有啥区别,加上以前玩微信机器人,所以打算以他俩的聊天记录模拟一个微信号给她。
(以前用的itchat协议被封了,这次换大佬弄的ipad协议)
| OS |
CPU |
GPU |
内存 |
基座模型 |
知识库 |
机器学习框架 |
| macOS 15.4.1 |
Apple M1 |
Apple M1 |
16G |
Qwen3-14B |
dify |
mlx |
导出微信聊天记录
找到聊天记录位置
1
| open ~/Library/Containers/com.tencent.xinWeChat/Data/Library/Application\ Support/com.tencent.xinWeChat/2.0b4.0.9
|
逆向微信
1、查看 SIP 状态
2、进入 Recovery 模式
3、关闭 SIP
4、attach到运行的 WeChat
1
| memory read --size 1--format
|
5、获取密钥
查看数据

对模型进行微调
数据处理
1
2
3
4
5
| {"prompt": "你好呀", "completion": "你好"}
{"prompt": "我是朋友介绍的 请问你要找对象吗 想认识一下可以吗", "completion": "6"}
{"prompt": "本来还想谈个恋爱 居然这么快就被识破了", "completion": "我有防撤回…"}
{"prompt": "好吧 其实我也想跟你咨询一下显卡的 可以吗 听说你好像是学计算机之类的专业", "completion": "我不是计算机的…"}
{"prompt": "可以吗", "completion": "下班了,回去再说"}
|
量化模型
1
2
3
4
5
| ➜ ~/Code/mlx-lm git:(main) ✗ mlx_lm.convert --hf-path Qwen/Qwen3-14B -q
[INFO] Loading
Fetching 15 files: 100%|██████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████████| 15/15 [00:00<00:00, 28301.65it/s]
[INFO] Quantizing
[INFO] Quantized model with 4.501 bits per weight.
|
训练
1
2
3
4
5
6
7
8
| ➜ ~/Code/mlx-lm git:(main) ✗ mlx_lm.lora --model mlx_model --train --data chat --batch-size 1 --num-layers 4
Loading pretrained model
Loading datasets
Training
Trainable parameters: 0.004% (0.524M/14770.034M)
Starting training..., iters: 600
Iter 1: Val loss 4.594, Val took 8.173s
Iter 10: Train loss 4.793, Learning Rate 1.000e-05, It/sec 1.693, Tokens/sec 31.829, Trained Tokens 188, Peak mem 8.422 GB
|
启动服务
openai api规范
1
2
| ➜ ~/Code/mlx-lm git:(main) ✗ mlx_lm.server --model mlx_model --adapter-path adapters --use-default-chat-template
2025-04-30 09:41:18,822 - INFO - Starting httpd at 127.0.0.1 on port 8080...
|
接入rag
部署dify
上传数据
微信接入ai
设置回调接口
1
2
3
4
5
6
7
| curl --location --request POST 'http://127.0.0.1:2531/v2/api/tools/setCallback' \
--header 'X-GEWE-TOKEN: 1a856e3f100e48bbaf8ff3cb68bfe3d8' \
--header 'Content-Type: application/json' \
--data-raw '{
"token": "1a856e3f100e48bbaf8ff3cb68bfe3d8",
"callbackUrl": "http://127.0.0.1:8888/v1/callback"
}'
|
最终效果